接触金融数据分析一段时间后发现,分析板块轮动、跟踪行业趋势,是做好A股投资分析的关键一步。不管是日常研判市场热点、筛选潜力赛道,还是试着搭建简单的分析模型,板块级别的数据都是不可或缺的核心依据。
可在使用、这两款主流工具时,我却遇到了最棘手的困扰——这两款工具只能提供个股的基础行情数据,偏偏没有现成的“板块指数生成”函数,无法直接将板块内所有个股的数据,汇总成能反映板块整体表现的指数数据。

起初我试着手动汇总板块内数十只个股的价格、成交量,可过程远比想象中繁琐:要逐个打开CSV文件提取数据,手动对齐日期避免停牌数据错位,逐行计算均值,稍有疏忽就会出错,算错一行就得全部重来,既耗时又耗力,好几次都因为手动计算的麻烦半途而废。
为了破解这个困扰,也为了提高自己的分析效率,我试着开发了ata函数,通过批量自动化处理本地存储的板块个股CSV数据,用均值计算的方式生成板块指数文件。本文将详细拆解该函数的实现逻辑、开发细节及拓展应用,希望能帮助和我一样,在板块数据获取上遇到阻碍的投资者和开发者,高效实现板块数据的自主生成。
1、问题的提出:和中没有现成的板块数据生成函数,为此编制了本函数
和是金融数据分析领域的常用工具:以“实时数据爬取”为核心,能获取A股个股的历史行情、财务数据;则侧重“批量历史数据导出”,可快速下载个股的K线、成交量等基础数据。但二者的核心短板在于——仅聚焦个股数据供给,未提供板块级数据的汇总生成能力。

在实际投资分析中,“板块指数”(如行业平均收盘价、平均成交量、平均涨跌幅)是判断板块强弱的关键:比如分析“新能源板块”的整体走势,需要汇总板块内所有个股的收盘价取平均,而非单独看某一只龙头股。如果依赖手动处理:
正是基于这一痛点,笔者编制了ata函数A股投资分析遇阻?教你开发函数自主生成板块指数数据,实现“本地板块个股数据→自动化汇总→板块指数文件”的全流程闭环,彻底替代手动计算,大幅提升板块数据分析效率。
2、生成板块数据的逻辑及关键代码展示
ata函数的核心逻辑是“目录遍历→文件筛选→数据累加→均值计算→文件保存”,通过批量处理本地存储的板块个股CSV文件,生成以“文件夹名(板块名)”命名的板块指数CSV文件。
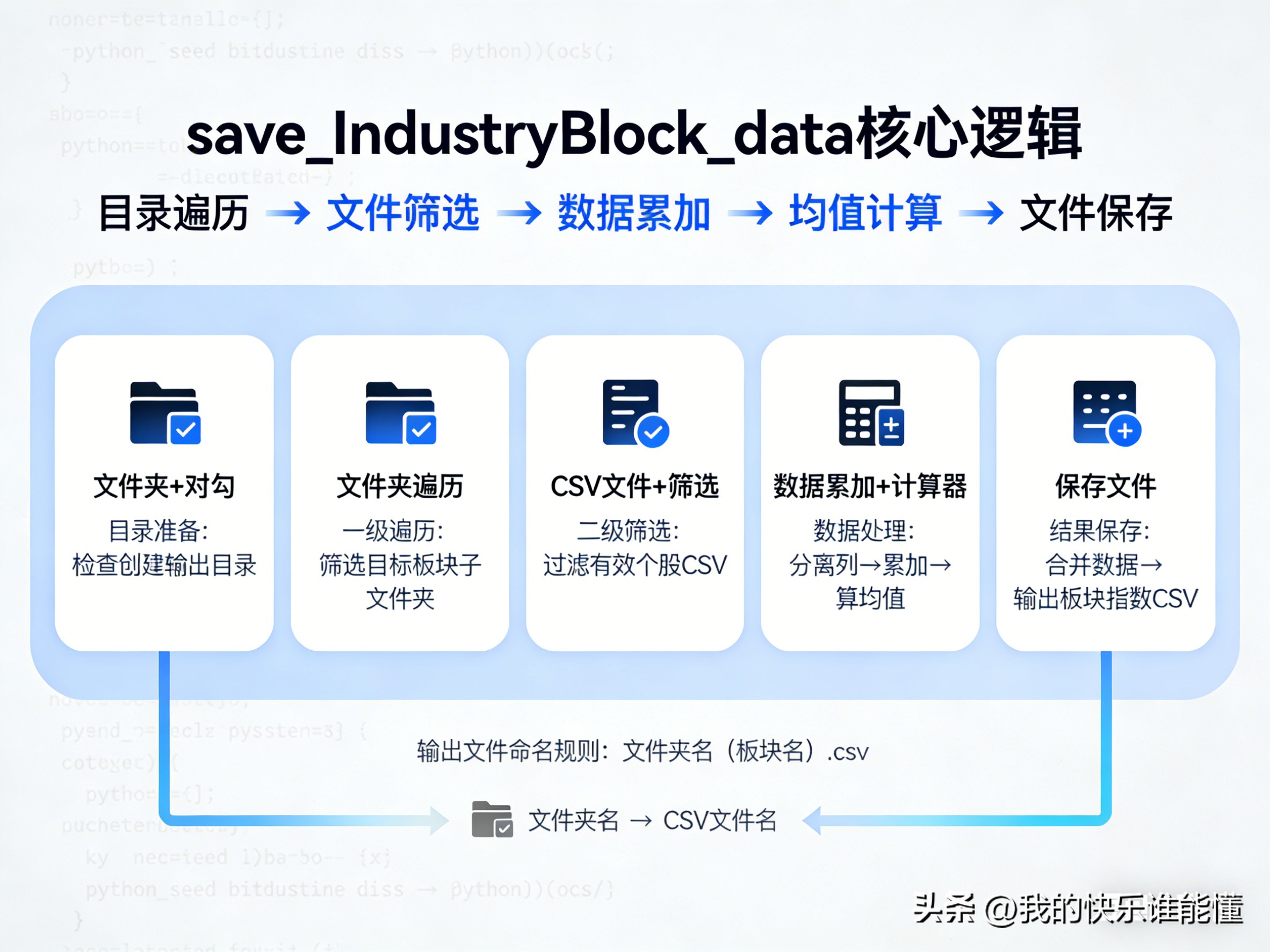
以下是核心逻辑拆解与关键代码解析:
2.1 整体逻辑框架
(1)目录准备:检查并创建板块指数输出目录,避免文件保存失败;
(2)一级遍历:遍历存储板块个股数据的主文件夹,过滤非目标子文件夹(如“未分类”“板块指数”);
(3)二级筛选:在目标子文件夹内筛选有效CSV文件(排除以文件夹名开头的无关文件);
(4)数据处理:分离“非计算列(日期、代码)”和“计算列(价格、成交量等)”,累加所有个股计算列后求均值;
(5)结果保存:合并日期、板块代码(文件夹名)、均值数据,保存为板块指数CSV文件。
2.2 关键代码展示与解析(1)目录准备与基础过滤
# 确保输出目录存在
if not os.path.():
os.()
# 第一层循环:遍历主文件夹下的每个子文件夹
for in os.():
= os.path.join(, )
# 仅处理文件夹,排除文件
if .(".csv"):
# 排除“未分类”、“板块指数”的文件夹
if in
"未分类","板块指数"
= os.path.()
print(f"\n{'='*50}")
print(f"正在处理文件夹:{}")
print(f"\n{'=' * 50}")
解析:首先确保输出目录(板块指数保存路径)存在,若不存在则自动创建;随后遍历存储板块数据的主文件夹,过滤掉CSV文件和非目标子文件夹(“未分类”“板块指数”),只保留有效板块文件夹,避免无关数据干扰。
(2)筛选有效CSV文件
# 第二层:获取该文件夹下所有.csv文件
= glob.glob(os.path.join(, "*.csv"))
if len() == 0:
print(f"文件夹{}中没有CSV文件,跳过……")
# 过滤掉以文件夹名开头的csv文件
=
for file in :
= os.path.(file)
# 排除以文件夹名开头的文件
if not .():
.(file)
解析:先获取文件夹内所有CSV文件,若为空则直接跳过;再过滤掉以文件夹名开头的文件(这类文件通常是板块的辅助数据,非个股行情),确保仅保留板块内个股的行情CSV文件。
(3)数据累加与均值计算
# 读取第一个文件,分离
不计算列
计算列
= pd.()
= .iloc.copy() # 前2列:日期、个股代码(非计算列)
= .iloc.copy() # 第3列起:价格、成交量等(计算列)
= .copy() # 初始化累加容器
# 累加所有个股的计算列
for file in :
= pd.(file)
if len(.) >= 3:
+= .iloc # 从第3列开始累加
# 求平均并保留2位小数
= / len()
= .round(2)
解析:以第一个个股文件为基准,分离“非计算列(日期、个股代码)”和“计算列(收盘价、成交量等)”;随后遍历所有个股文件,累加计算列数据;最后用累加结果除以个股数量,得到板块均值(保留2位小数,符合金融数据展示习惯)。
(4)合并数据并保存
# 创建板块代码列(值为文件夹名)
= pd.(
* len(), name=.)
# 获取日期列
= .iloc
# 合并列:日期 + 板块代码 + 均值计算列
= pd.(
, ,
, axis=1)
# 保存板块指数文件
= os.path.join(, f"{}_avg.csv")
.(, index=False, ="utf-8-sig")
解析:将“日期列”“板块代码列(文件夹名)”“均值计算列”合并,生成板块指数数据框;最后保存为CSV文件(编码为utf-8-sig,避免中文乱码),文件命名为“板块名_avg.csv”,便于后续检索。
3、关键细节
ata函数的稳定性和实用性,依赖于多个开发细节的把控,这些细节也是金融数据处理中需要重点关注的点:
3.1 容错处理:避免程序中断
函数加入了多层容错逻辑:
3.2 数据维度对齐:确保计算准确性
板块内个股的行情数据可能存在日期缺失(如个股停牌),但函数通过“以第一个文件的日期列为基准”的方式,确保所有个股的计算列都基于相同日期维度累加,避免因日期错位导致的均值偏差。
3.3 可视化提示:提升调试效率
函数在关键节点打印提示信息:
这些提示便于开发者监控处理进度,快速定位异常板块。
3.4 目录隔离:避免数据污染
函数明确排除“未分类”“板块指数”文件夹:
3.5 多文件内列数据计算
多文件内列数据的精准计算,是板块指数生成的核心环节,也是新手最易出错的地方。本小节重点阐述多文件字段求和实现、新CSV文件数据组合方式及计算精度控制,核心贴合本次函数实操,精简冗余内容,聚焦关键方法。
一是多文件字段求和方法,也是板块指数计算的核心。本程序中,以第一个个股CSV文件为基准,先分离出第3列及以后的计算字段(开盘价、收盘价等数值字段),初始化累加容器;随后遍历剩余所有CSV文件,仅提取各文件的计算字段(通过iloc定位),逐单元格累加,确保所有个股的对应数值字段精准叠加,避免非计算字段干扰,为后续均值计算奠定基础。
多文件字段求和核心代码# 核心:仅对第3列及以后计算字段累加(关键代码片段)
= .iloc.copy() # 初始化累加容器(取第一个文件计算列)
for file in :
= pd.(file)
if len(.) >= 3: # 容错:确保有计算列
# 仅累加第3列及以后的数值字段,跳过前2列非计算字段
+= .iloc
代码核心是通过iloc精准定位计算字段,避免误加前2列(日期、个股代码),同时增加列数校验,提升程序稳定性。
二是新CSV文件数据组合方法,明确区分三类字段并规范组合逻辑:不计算字段(前2列:日期、个股代码),直接保留第一个文件的日期列,个股代码列替换为新生成字段——板块代码列(值统一为对应板块文件夹名);计算字段(第3列起),将所有文件累加后的结果除以文件个数,得到平均后的数值字段;三者按“日期列→板块代码列→平均后计算字段”的顺序组合,生成最终的板块指数CSV文件,确保数据结构清晰、贴合分析需求。
新CSV文件数据组合核心代码# 1. 提取不计算字段(日期列)
= .iloc.copy() # 保留第一个文件的日期列
# 2. 生成新字段(板块代码列)
= pd.(
*len(),)
# 3. 计算平均后的数值字段
= / len()
# 4. 组合三类字段,生成新CSV数据
= pd.(
, ,
, axis=1)
代码清晰区分三类字段的处理逻辑,组合后的数据结构与原个股CSV一致,仅将个股代码替换为板块代码,计算列替换为板块均值,便于后续检索使用。
三是计算精度控制方法,兼顾准确性与规范性。累加过程中保留所有原始数据精度,不提前 ,避免多次精度取舍导致的累计误差;待所有文件字段累加完成、计算出均值后,通过round(2)方法保留2位小数,既符合金融数据的常规展示规范,也能最大程度降低精度损耗,确保板块指数数据的准确性。
计算精度控制核心代码# 精度控制:累加不提前取整,均值后保留2位小数
= ( / len()).round(2) # 关键:仅在最终均值后取整
# 可选:强制转为数值型,避免科学计数法(适配金融数据展示)
= .(float)
代码核心是“累加保精度、均值再取整”,避免多次round导致的累计误差,同时兼容金融数据的常规展示需求,新手可直接复用。
4、拓展应用:重点阐述生成的csv文件在板块数据检索、分析方面的应用
通过ata函数生成的板块指数CSV文件,可在多个场景下发挥价值,核心应用集中在“数据检索”和“分析决策”两大方向:
4.1 板块数据快速检索
结合程序中的函数,可实现板块指数的快速检索:
# 检索“新能源板块”2025年1月1日至2月14日的指数数据
df = ("新能源_avg","2025/1/01","2025/2/14")
print(df)
只需传入“板块名_avg”作为标的代码,即可快速获取指定日期范围的板块指数数据,替代手动打开CSV文件筛选数据的低效方式。检索结果可直接用于后续分析,无需额外数据清洗。
4.2 板块趋势分析
板块指数CSV文件包含“日期、板块代码、收盘价、成交量、涨跌幅”等核心列,可结合、等库绘制趋势图:
4.3 板块间强弱对比
将不同板块的指数数据汇总后,可实现板块间的强弱对比:
4.4 量化交易策略开发
板块指数数据可作为量化策略的核心输入:
4.5 数据备份与团队共享
生成的板块指数CSV文件是结构化的静态数据,具备两大优势:
总结
ata函数的核心价值,在于填补了、等工具在“板块指数生成”环节的空白股票代码一览表下载,实现了从“个股数据”到“板块数据”的自动化转化。对于普通投资者而言,该函数降低了板块数据分析的门槛,无需掌握复杂的编程技巧即可获取标准化的板块指数;对于专业开发者而言,函数的模块化设计可灵活拓展(如修改均值计算为加权平均、加入更多维度的计算列),适配不同的分析需求。

在A股市场中,板块趋势往往比个股走势更具参考价值。通过自主生成板块指数数据,投资者可摆脱对第三方数据平台的依赖,构建个性化的板块分析体系,从而更精准地把握市场节奏,提升投资决策的科学性。



